- Python
- Swift
- TypeScript
- Rust
1
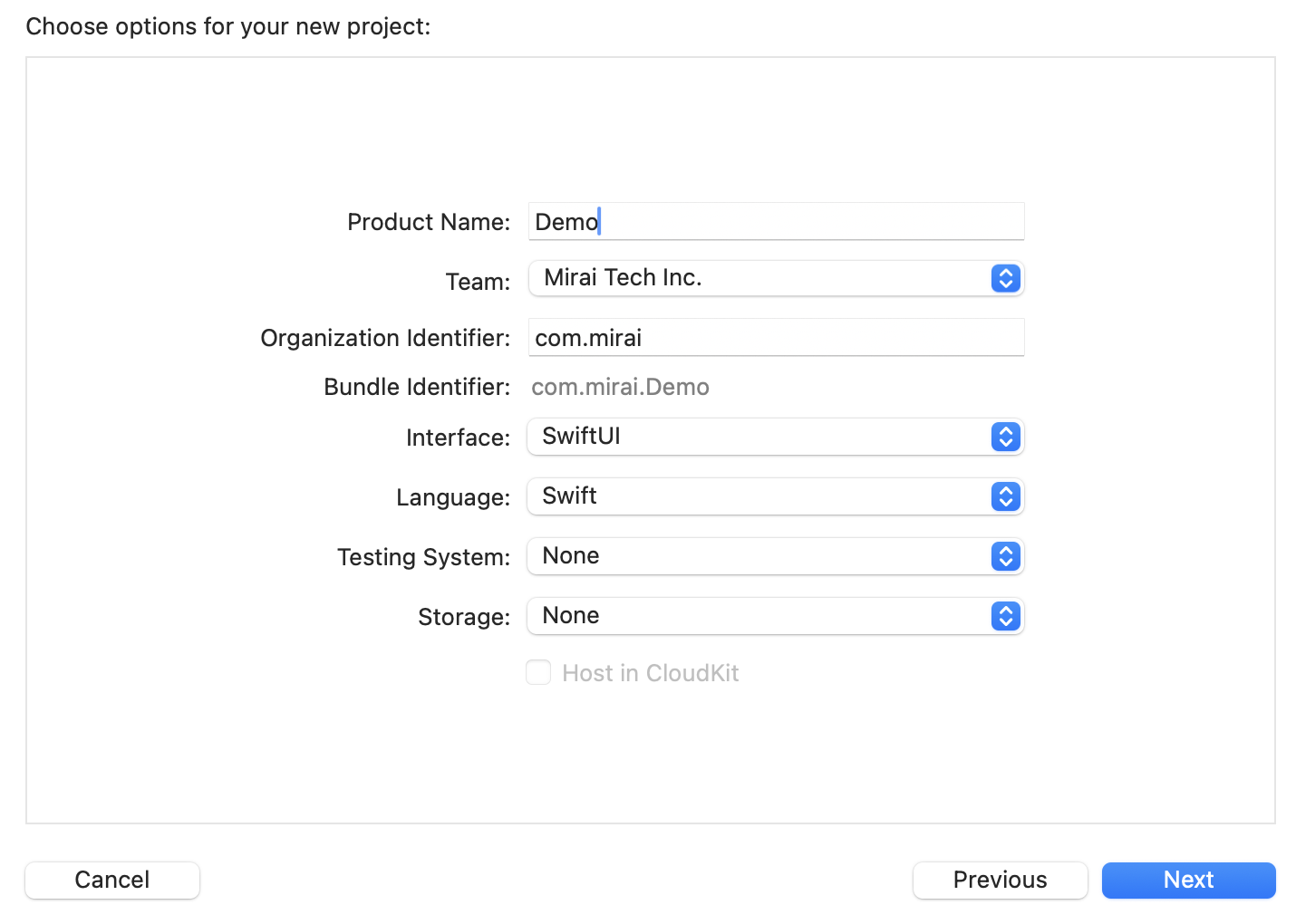
Create a new project
2
Install dependencies
3
Paste into main.py
4
Run the snippet
You can view the stats to see that the answer will be ready immediately after the prefill step, and actual generation won’t even start due to speculative decoding, which significantly improves generation speed.